An AI startup and MIT spinoff, Liquid AI, co-founded by former researchers from the Massachusetts Institute of Technology (MIT)’s Computer Science and Artificial Intelligence Laboratory (CSAIL), announced its first set of generative AI models called “Liquid Foundation Models,” or LFMs.
The new models are built on a fundamentally new architecture and are built from “first principles…the same way engineers built engines, cars, and airplanes.”
They are said to deliver impressive performance, surpassing even the traditional and some of the best large language models, such as Meta’s Llama 3.1-8B and Microsoft’s Phi-3.5 3.8B.
Liquid AI is releasing three models at launch:
The startup believes new models have shown exceptional results, showing a smaller memory footprint for long-context processing.
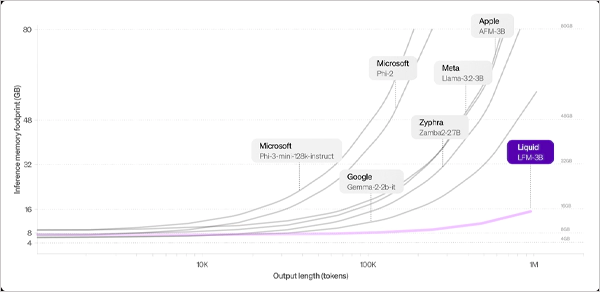
These models are expected to become formidable competitors to generative AI models such as ChatGPT.
However, the new models are not open source, and thus they are available in early access via platforms, such as Liquid’s inference playground, Lambda Chat, or Perplexity AI.
According to Liquid, LFMs represent a new wave of AI models that are designed to deliver both efficiency and performance while using minimal system memory and delivering exceptional computing power. It is said they are ideal for handling sequential data, including text, audio, images, video, and signals.
LNNs are based on the concept of artificial neurons, and thus they combine those neurons with innovative mathematical formulations to transform data with the same performance but fewer neurons.
